Covered Index : 출력되어야 하는 모든 컬럼이 인덱스 구성에 포함되어 있는 경우.
Include Index : 키가 아닌 열을 포함하여 여러 쿼리를 처리하는 비클러스터형 인덱스를 만드는 것.
키가 아닌 열은 인덱스 키 열로 사용할 수 없는 데이터 형식입니다.
인덱스 키 열의 수 또는 인덱스 키 크기를 계산할 때데이터베이스 엔진은 키가 아닌 열을 고려하지 않습니다.
쿼리의 모든 열이 키 열 또는 키가 아닌 열로 인덱스에 포함되면 키가 아닌 열이 있는 인덱스는 쿼리 성능을 상당히 향상시킬 수 있습니다.성능이 향상되는 이유는 쿼리 최적화 프로그램이 테이블 또는 클러스터형 인덱스 데이터에 액세스하지 않고 인덱스 내에서 모든 열 값을 찾을 수 있으므로 디스크 I/O 작업을 줄어들기 때문입니다.
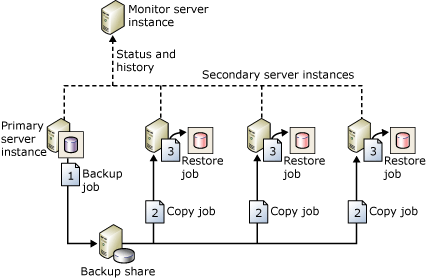
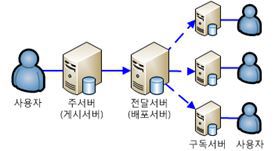
복제는 한 데이터베이스에서 다른 데이터베이스로 데이터와 데이터베이스 개체를 복사 및 배포한 다음 데이터베이스 간에 동기화를 수행하여 일관성을 유지하는 일련의 기술
(1) 스냅샷 복제 - 많은 양의 데이터가 변경되지만 자주 변경되지는 않을 때 가장 적합. 단독으로 사용할 수 있지만 게시에서 지정한 모든 개체 및 데이터의 복사본을 만드는 스냅샷 프로세스는 일반적으로 트랜잭션 및 병합 게시에 대한 초기 데이터 및 데이터베이스 개체 집합을 제공하는 데에도 사용
(2) 트랜잭션 복제 - 스냅샷 복제로 데이터 동기화 이후, 데이터 변경과 스키마 변경을 로그 판독기 에이전트가 수집하여 배포 DB에 기록하면 구독자에게 반영. 실시간 동기화가 된다. 일반적으로 확장성 및 가용성 향상, 데이터 웨어하우징 및 보고, 여러 사이트의 데이터 통합, 다른 유형의 데이터 통합, 일괄 처리 작업 오프로드 등을 포함하여 높은 처리량이 필요한 서버 간 시나리오에서 사용.
(3) 병합 복제 - 게시자와 구독자의 데이터 변경과 스키마 변경내용을 트리거로 추적해서 변경 추적 테이블에 기록하고, 그 내용을 병합해서 게시자와 구독자에 반영. 관리가 다소 복잡. 주로 데이터 충돌 가능성이 있는 모바일 애플리케이션이나 분산 서버 애플리케이션에 사용됩니다.일반적인 시나리오에는 모바일 사용자와 데이터 교환, 소비자 POS(Point of Sale) 애플리케이션, 여러 사이트의 데이터 통합 등이 있음.
(4) 피어 투 피어 복제 - 노드(Node)라고 하는 여러 SQL Server 인스턴스로 DB 복제본을 유지 관리. 확장성과 고가용성 이점. 모든 데이터를 복제. 거의 실시간으로 일관되게 전파.
동적 관리 뷰 및 함수는 서버 인스턴스 상태 모니터링, 문제 진단 및 성능 튜닝에 사용할 수 있는 서버 상태 정보를 반환합니다.
동적 관리 뷰 또는 함수를 쿼리하려면 개체에 대한 SELECT 권한과 VIEW SERVER STATE 또는 VIEW DATABASE STATE 권한이 필요합니다.
- 동적관리뷰 개수는? : 아래 쿼리를 활용하여 확인해보니 총 273개입니다.
SELECT N'SYS.' + NAME AS NAME, TYPE_DESC
FROM SYS.SYSTEM_OBJECTS
WHERE NAME LIKE N'DM[_]%'
ORDER BY NAME
모두를 알기는 불가능하니, 자주 쓰는 DMV에 대해서 알아보겠습니다.
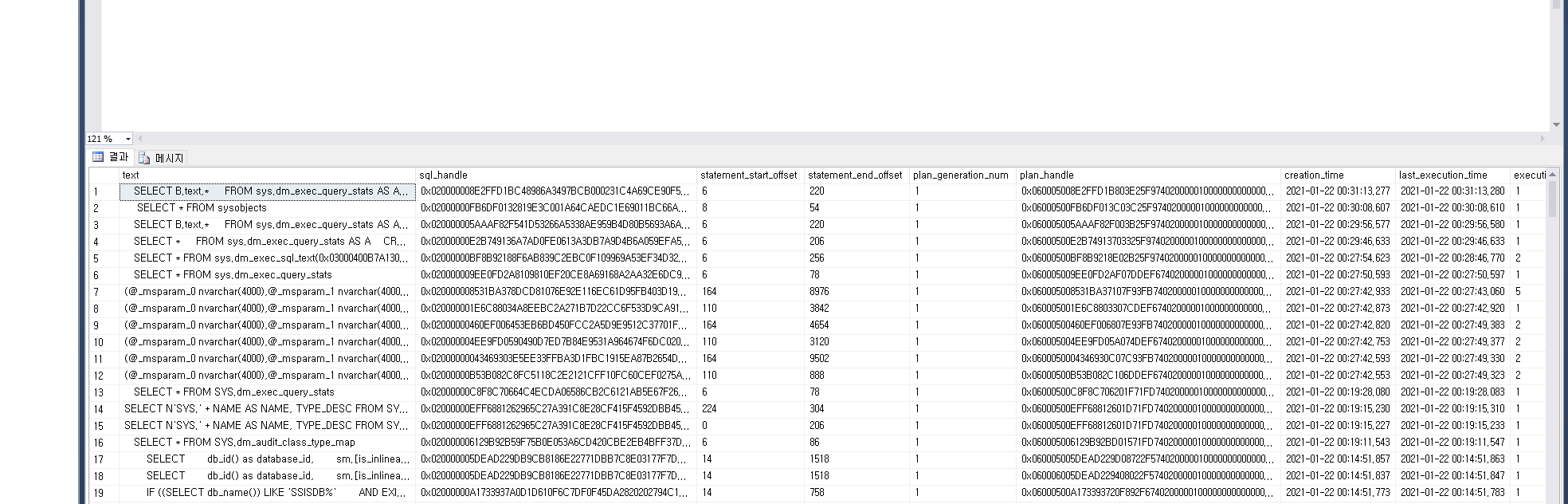
(1) sys.dm_exec_query_stats - 캐시된 쿼리 계획에 대한 집계 성능 통계
ex - 평균 CPU 시간별로 상위 5개의 쿼리 찾기
SELECT TOP 5 query_stats.query_hash AS "Query Hash",
SUM(query_stats.total_worker_time) / SUM(query_stats.execution_count) AS "Avg CPU Time",
MIN(query_stats.statement_text) AS "Statement Text"
FROM (SELECT QS.*, SUBSTRING(ST.text, (QS.statement_start_offset/2) + 1,
((CASE statement_end_offset WHEN -1 THEN DATALENGTH(ST.text)
ELSE QS.statement_end_offset END
- QS.statement_start_offset)/2) + 1) AS statement_text
FROM sys.dm_exec_query_stats AS QS
CROSS APPLY sys.dm_exec_sql_text(QS.sql_handle) as ST) as query_stats
GROUP BY query_stats.query_hash
ORDER BY 2 DESC;
(2) sys.dm_exec_sql_text(sql_handle) - 지정 된sql_handle에 의해 식별 되는 SQL 일괄 처리의 텍스트를 반환
- text 컬럼에 SQL 쿼리 실행 텍스트가 나옴.
SELECT B.text,*
FROM sys.dm_exec_query_stats AS A
CROSS APPLY sys.dm_exec_sql_text(A.sql_handle) AS B
ORDER BY A.creation_time DESC
(3) sys.dm_exec_procedure_stats - 저장 프로시저에 대한 집계 성능 통계
- 평균 경과 시간으로 식별된 상위 10개의 저장 프로시저 찾기 예제
SELECT TOP 10 d.object_id, d.database_id, OBJECT_NAME(object_id, database_id) 'proc name',
d.cached_time, d.last_execution_time, d.total_elapsed_time,
d.total_elapsed_time/d.execution_count AS [avg_elapsed_time],
d.last_elapsed_time, d.execution_count
FROM sys.dm_exec_procedure_stats AS d
ORDER BY [total_worker_time] DESC;
(4) sys.dm_exec_requests - 실행 되는 각 요청에 대한 정보를 반환
(5) sys.dm_exec_query_plan - 계획 핸들로 지정한 일괄 처리에 대한 XML 형식의 실행 계획을 반환
10. 백업 종류 (1) 전체 백업 : DB의 모든 데이터를 백업. 백업이 진행되는 동안 발생한 트랜잭션 로그도 백업.
(2) 차등 백업 : 전체 백업 이후 백업되지 않은 변경된 데이터만 백업.
(3) 트랜잭션 로그 백업 : 트랜잭션 로그 파일을 백업하고 로그를 지움. 설정으로 안지울수 있다. FULL, BULK_LOGGED 복구모델만 가능
(4) 로그 꼬리 백업 : 백업되지 않고 남아있는 로그를 백업. 마지막 로그 백업
(5) 파일/파일 그룹 백업 : 데이터베이스 크기가 커서 파일 또는 파일그룹을 백업.
(6) 부분 백업 : 파일 그룹 중 PRIMARY 파일 그룹과 읽기/쓰기가 가능한 파일 그룹을 백업. (OR 명시적으로 읽기 전용 파일 그룹도 포함해서 가능)
(7) 복사 전용 백업 : 다른 백업에 영향을 끼치지 않고 전체 백업이나 트랜잭션 로그 백업을 할 수 있다.
11. 복구 모델
(1) 전체(FULL) : 모든 데이터 변경에 대한 로그를 트랜잭션 로그 파일에 기록. 특정시점 복원이 가능. 로그 파일 용량이계속 커지므로 관리 필요.
(2) 대량로그(BULK_LOGGED) : 대량 로그 작업으로 발생하는 트랜잭션 로그를 최소화하여 작업을 빠르게. BCP, BULK INSERT, INSERT~ SELECT, CREATE INDEX, ALTER INDEX REBUILD 등. 대량로그 작업이 발생하면 특정시점으로 복원 할 수 없다. 디스크 성능이 좋아짐에 따라 잘 쓰지 않음.
자동 닫기(AUTO_CLOSE) : 기본OFF. ON이면 마지막 사용자가 끝낸 후 데이터베이스가 종류되고 리소스가 해제 됨.
자동 축소(AUTO_SHRINK) : 기본 OFF. ON이면 파일에서 사용되지 않는 공간이 25% 이상 일 때 파일을 자동으로 축소함.
증분 통계 자동 작성(INCREMENTAL) : 기본 OFF. ON이면 AUTO_CREATE_STATISTICS가 ON일 경우 파티션별로 통계 생성.
통계 자동 작성(AUTO_CREATE_STATISTICS) : 기본 ON. ON이면 쿼리 최적화에 필요한 누락된 통계가 최적화 동안 모두 자동으로 작성 됨.
통계 자동 업데이트(AUTO_UPDATE_STATISTICS) : 기본 ON. ON이면 쿼리 최적화에 필요한 오래된 통계가 모두 자동으로 업데이트 됨.
통계 비동기 자동 업데이트(AUTO_UPDATE_STATISTICS_ASYNC) : 기본 OFF. ON이면 AUTO_UPDATE_STATISTICS 옵션에 의한 통계 업데이트가 비동기로 수행 됨. 쿼리 최적화 프로그램이 쿼리를 컴파일 할 때 통계 업데이트가 완료될 때까지 기다리지 않음.
(2) 상태 옵션
데이터베이스 상태(OFFLINE | ONLINE | EMERGENCY) : OFFLINE - DB 종료, ONLINE - DB 열림, EMERGENCY - 로그파일이 손상되어 "주의 대상"으로 표시된 DB를 읽을 수 있음.
액세스 제한 (SINGLE_USER | RESTRICTED_USER | MULTI_USER) : SINGLE_USER - 한명만 가능, RESTRICTED_USER - db_owner 고정 DB 역할. dbcreator, sysadmin 고정 서버역할 멤버만 접속 가능, MULTI_USER - 여러명 가능
(3) 복구 옵션
복구모델 : 전체(FULL) - 전체복구, 대량로그(BULK_LOGGED) - 특정 대량 작업에 대해 로그공간 최소. 대량작업성능UP, 단순(SIMPLE) - 최소의 로그 공간 사용. 로그 백업 불가.
페이지확인(PAGE_VERIFY) : CHECKSUM - 전체 페이지 내용에 대한 체크섬 계산 후 페이지헤더에 저장 이후 비고, TORN_PAGE_DETECTION - 페이지 8KB중 512Byte 섹터에 대해 특정 2bit 패턴을 페이지 헤더에 저장 이후 비교, NONE - 페이지 확인 하지 않음.
예를 들어 세 개의 디스크 드라이브에 Data1.ndf, Data2.ndf, Data3.ndf를 각각 만들어 fgroup1이라는 파일 그룹에 할당
그런 다음 fgroup1 파일 그룹에 한 개의 테이블을 만들 수 있습니다.
이렇게 하면 해당 테이블의 데이터에 대한 쿼리가 3개의 디스크로 분산되므로 성능이 향상됩니다.
(1) 기본(주) 파일 그룹(PRIMARY FILE GROUP)
PRIMARY 파일 그룹. 주 파일을 포함하는 파일 그룹.모든 시스템 테이블은 주 파일 그룹의 일부입니다.
(2) 사용자 정의 파일그룹(User-defined File Groups)
사용자가 데이터베이스를 처음 만들거나 나중에 수정할 때 만드는 파일 그룹입니다.
8. 파일 그룹 추가
(1) 데이터베이스 속성 사용
(2) 스크립트 사용
USE master
GO
-- FirstDB02에 UFG01 사용자 정의 파일 그룹 추가
ALTER DATABASE FirstDB02 ADD FILEGROUP UFG01
GO
-- UFG01 파일 그룹에 파일 추가
ALTER DATABASE FirstDB02
ADD FILE
(
NAME = 'FirstDB02_02',
FILENAME = 'C:\SQLDATA\FirstDB02_02.ndf',
SIZE = 512MB,
FILEGROWTH = 128MB
)
GO
-- UFG01 파일 그룹을 기본 파일 그룹으로 변경
ALTER DATABASE FirstDB02
MODIFY FILEGROUP UFG01 DEFAULT
GO