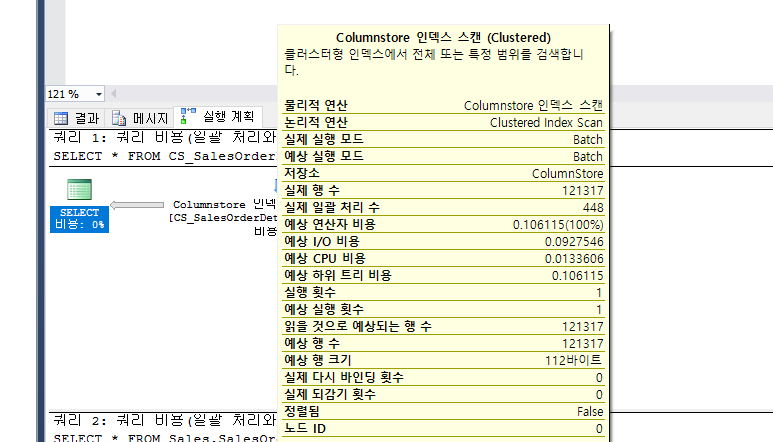
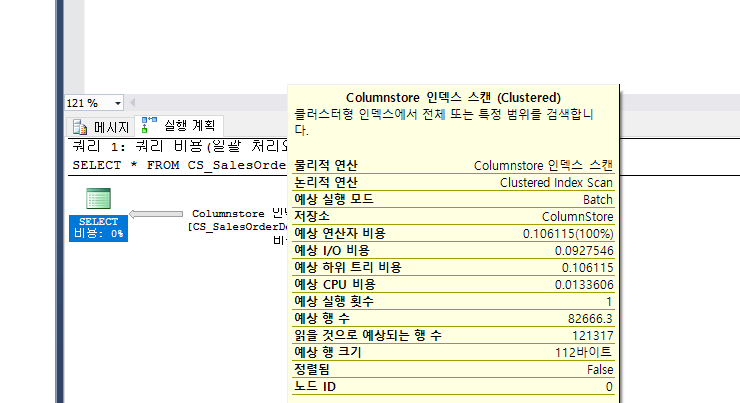
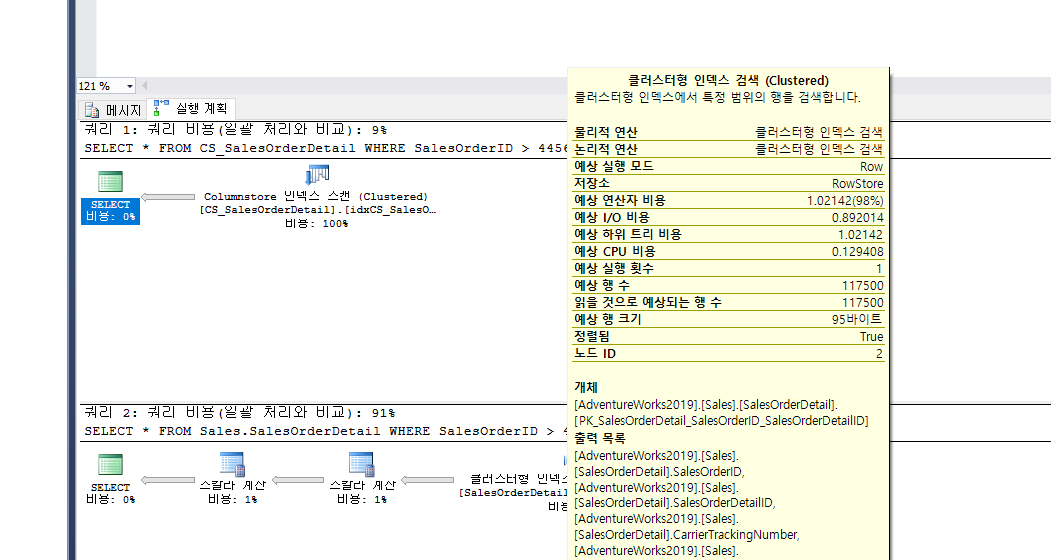
메모리 내 columnstore 인덱스는 열 기반 데이터 스토리지 및 열 기반 쿼리 처리를 사용하여 데이터를 저장하고 관리합니다.
columnstore 인덱스는 주로 대량 로드 및 읽기 전용 쿼리를 수행하는 데이터 웨어하우징 작업에 효과적입니다.columnstore 인덱스를 사용하면 기존의 행 기반 스토리지보다 최대10배의 쿼리 성능이익과 압축되지 않은 데이터 크기보다 최대7배의 데이터 압축을 얻을 수 있습니다.
(1) 생성 방법
클러스터 인덱스 기준
CREATE CLUSTERED COLUMNSTORE INDEX "idx명" ON "테이블명"
CREATE CLUSTERED COLUMNSTORE INDEX idxCS_SalesOrderDetail ON CS_SalesOrderDetail
Covered Index : 출력되어야 하는 모든 컬럼이 인덱스 구성에 포함되어 있는 경우.
Include Index : 키가 아닌 열을 포함하여 여러 쿼리를 처리하는 비클러스터형 인덱스를 만드는 것.
키가 아닌 열은 인덱스 키 열로 사용할 수 없는 데이터 형식입니다.
인덱스 키 열의 수 또는 인덱스 키 크기를 계산할 때데이터베이스 엔진은 키가 아닌 열을 고려하지 않습니다.
쿼리의 모든 열이 키 열 또는 키가 아닌 열로 인덱스에 포함되면 키가 아닌 열이 있는 인덱스는 쿼리 성능을 상당히 향상시킬 수 있습니다.성능이 향상되는 이유는 쿼리 최적화 프로그램이 테이블 또는 클러스터형 인덱스 데이터에 액세스하지 않고 인덱스 내에서 모든 열 값을 찾을 수 있으므로 디스크 I/O 작업을 줄어들기 때문입니다.
원본 데이터베이스의 데이터를 다른 데이터베이스로 복사한 후, 이를 동기화시켜 사용할 수 있게(대부분 읽기전용으로 사용)하는 것
복제를 위한 서버의 역할
게시자
다른서버에 동기화될 데이터가 포함된 원본 데이터베이스를 유지 관리하는 서버
배포자
게시자가 제공하는 게시를 가져와 구독자에게 배포하는 역할을 맡은 서버
※ 대부분 서버 하나가 게시자와 배포자 역할을 동시에 담당하는데, 이를 '로컬 배포자'라고 합니다.
구독자
게시되는 데이터를 받거나 가져가는 서버
# 복제 유형
스냅숏 복제(Snapshot Replication)
복제를 구성하면 게시 전체를 구독자에게 정기적으로 보내서 동기화한다.
스냅샷 복제는 특정 시간에 나타나는 그대로 데이터를 배포하고 데이터 업데이트를 모니터링하지 않습니다.동기화가 일어나면 전체 스냅샷이 생성되어 구독자에게 전송됩니다.
참고
스냅샷 복제는 단독으로 사용할 수 있지만 게시에서 지정한 모든 개체 및 데이터의 복사본을 만드는 스냅샷 프로세스는 일반적으로 트랜잭션 및 병합 게시에 대한 초기 데이터 및 데이터베이스 개체 집합을 제공하는 데에도 사용됩니다.
다음 조건 중 하나 이상이 해당될 경우 스냅샷 복제를 단독으로 사용하는 것이 좋습니다.
데이터가 자주 변경되지 않습니다.
게시자 측에서 최신이 아닌 데이터 복사본을 일정 기간 동안 보유할 수 있습니다.
소량의 데이터를 복제합니다.
짧은 기간 동안 많은 양의 데이터가 변경됩니다.
트랜잭션 복제(Transactionsal Replication)
스냅숏 복제를 한 후, 데이터 변경과 스키마 변경 내용을1)로그 판독기 에이전트가 수집해 배포 데이터베이스에 기록하면,2)배포 에이전트가 그 내용을 읽어 구독자에 반영하여, 일관된 데이터 상태를 유지하는 유형
-> 거의 실시간 동기화를 수행!
트랜잭션 복제는 일반적으로 게시 데이터베이스 개체 및 데이터의 스냅샷으로 시작됩니다.일반적으로 초기 스냅샷이 사용되자마자 게시자에서의 후속 데이터 변경 내용 및 스키마 수정 내용이 구독자로 배달됩니다. 이러한 작업은 거의 실시간으로 수행됩니다.데이터 변경 내용은 게시자에서 발생한 것과 같은 순서 및 같은 트랜잭션 경계 내에서 구독자에 적용되므로 게시 내에서는 트랜잭션 일관성이 보장됩니다.
트랜잭션 복제는 일반적으로 서버 간 환경에 사용되며 다음과 같은 경우에 적합합니다.
증분 변경 내용을 발생과 동시에 구독자로 전파하려고 합니다.
애플리케이션이 게시자에서 변경이 수행된 시점과 해당 변경 내용이 구독자에 도달한 시점 간의 짧은 대기 시간이 필요합니다.
애플리케이션이 중간 데이터 상태에 액세스해야 합니다.예를 들어 한 행이 5번 변경될 경우 트랜잭션 복제를 사용하면 애플리케이션은 행의 실질적인 데이터 변경만이 아닌 모든 변경(예: 트리거 실행)에 응답할 수 있습니다.
게시자가 많은 양의 삽입, 업데이트 및 삭제 작업을 수행합니다.
게시자 또는 구독자가 Oracle과 같은SQL Server이외의 데이터베이스입니다.
기본적으로 변경 내용은 게시자로 다시 전파되지 않기 때문에 트랜잭션 게시에 대한 구독자는 읽기 전용으로 취급됩니다.그러나 트랜잭션 복제는 구독자의 업데이트를 허용하는 다양한 옵션을 제공합니다.
병합 복제(Merge Replication)
트리거를 이용하여 게시자와 구독자의 변경 내용을 변경 추적 테이블에 기록하는 유형
피아 투 피어 복제(Peer To Peer Replication)
여러 SQL Server 인스턴스에 걸쳐 데이터베이스 복제본을 유지 관리해서, 확장성과 고가용성의 이점을 제공하는 복제 유형
SQL Server는 하나의 인스턴스 당 최고 32,767개의 데이터베이스를 정의해 사용할 수 있다. 기본적으로 master, model, msdb, tempdb 등의 시스템 데이터베이스가 만들어지며, 여기에 사용자 데이터베이스를 추가로 생성하는 구조다.
데이터베이스 하나를 만들 때마다 주(Primary 또는 Main) 데이터 파일과 트랜잭션 로그 파일이 하나씩 생기는데, 전자는 확장자가 mdf이고 후자는 ldf이다. 저장할 데이터가 많으면 보조(Non-Primary) 데이터 파일을 추가할 수 있으며, 확장자는 ndf이다.
작업의 논리적 단위가 단일 연산이 아닐 수 있다. 즉, 하나의 트랜잭션이 두 개 이상의 갱신 연산일 수 있다. 은행의 “계좌이체” 트랜잭션을 예로 들면, 하나의 예금 계좌에서 인출하여 다른 예금 계좌에 입금하는 일련의 작업을 하나의 단위로 수행해야 한다. 데이터를 일관성 있게 처리하려면 트랜잭션에 속한 두 개 이상의 갱신 연산을 동시에 실행할 수 있어야 하는데, 불행히도 이는 불가능한 일이다. 따라서 DBMS는 차선책을 사용한다. 즉, 여러 개의 갱신 연산이 하나의 작업처럼 전부 처리되거나 아예 하나도 처리되지 않도록(All or Nothing) 동시 실행을 구현한다.
1. 트랜잭션의 특징
데이터베이스의 갱신과 관련하여 트랜잭션은 아래와 같은 4가지 주요 특징을 가지며, 영문 첫 글자를 따서 ‘ACID’라고 부른다.
원자성(Atomicity) 트랜잭션은 더 이상 분해가 불가능한 업무의 최소단위이므로, 전부 처리되거나 아예 하나도 처리되지 않아야 한다.
일관성(Consistency) 일관된 상태의 데이터베이스에서 하나의 트랜잭션을 성공적으로 완료하고 나면 그 데이터베이스는 여전히 일관된 상태여야 한다. 즉, 트랜잭션 실행의 결과로 데이터베이스 상태가 모순되지 않아야 한다.
격리성(Isolation) 실행 중인 트랜잭션의 중간결과를 다른 트랜잭션이 접근할 수 없다.
영속성(Durability) 트랜잭션이 일단 그 실행을 성공적으로 완료하면 그 결과는 데이터베이스에 영속적으로 저장된다.
2. 트랜잭션 격리성
트랜잭션의 격리성은, 일관성과 마찬가지로 Lock을 강하게 오래 유지할수록 강화되고, Lock을 최소화할수록 약화된다. 낮은 단계의 격리성 수준에서 어떤 현상들이 발생하는지부터 살펴보자.
가.
- 낮은 단계의 격리성 수준에서 발생할 수 있는 현상들
1) Dirty Read
다른 트랜잭션에 의해 수정됐지만 아직 커밋되지 않은 데이터를 읽는 것을 말한다. 변경 후 아직 커밋되지 않은 값을 읽었는데 변경을 가한 트랜잭션이 최종적으로 롤백된다면 그 값을 읽은 트랜잭션은 비일관된 상태에 놓이게 된다.
2) Non-Repeatable Read
한 트랜잭션 내에서 같은 쿼리를 두 번 수행했는데, 그 사이에 다른 트랜잭션이 값을 수정 또는 삭제하는 바람에 두 쿼리 결과가 다르게 나타나는 현상을 말한다.([그림 Ⅲ-2-1] 참조)
[그림 Ⅲ-2-1]에서 t1 시점에 123번 계좌번호의 잔고는 55,000원이었다고 가정하자. ①번 쿼리를 통해 자신의 계좌에 55,000원이 남아 있음을 확인하고 t4 시점에 10,000원을 인출하려는데, 중간에 TX2 트랜잭션에 의해 이 계좌의 잔고가 5,000원으로 변경되었다. 그러면 TX1 사용자는 잔고가 충분한 것을 확인하고 인출을 시도했음에도 불구하고 잔고가 부족하다는 메시지를 받게 된다.
3) Phantom Read
한 트랜잭션 내에서 같은 쿼리를 두 번 수행했는데, 첫 번째 쿼리에서 없던 유령(Phantom) 레코드가 두 번째 쿼리에서 나타나는 현상을 말한다.
[그림 Ⅲ-2-2]에서 TX1 트랜잭션이 지역별고객과 연령대별고객을 연속해서 집계하는 도중에 새로운 고객이 TX2 트랜잭션에 의해 등록되었다. 그 결과, 지역별고객과 연령대별고객 두 집계 테이블을 통해 총고객수를 조회하면 서로 결과 값이 다른 상태에 놓이게 된다.
나.
# 트랜잭션 격리성 수준
ANSI/ISO SQL 표준(SQL92)에서 정의한 4가지 트랜잭션 격리성 수준(Transaction Isolation Level)은 다음과 같다.
Read Uncommitted 트랜잭션에서 처리 중인 아직 커밋되지 않은 데이터를 다른 트랜잭션이 읽는 것을 허용한다
Read Committed 트랜잭션이 커밋되어 확정된 데이터만 다른 트랜잭션이 읽도록 허용함으로써 Dirty Read를 방지해준다. 커밋된 데이터만 읽더라도 Non-Repeatable Read와 Phantom Read 현상을 막지는 못한다. 읽는 시점에 따라 결과가 다를 수 있다는 것이다. 한 트랜잭션 내에서 쿼리를 두 번 수행했는데 두 쿼리 사이에 다른 트랜잭션이 값을 변경/삭제하거나 새로운 레코드를 삽입하는 경우로서, [그림 Ⅲ-2-1]과 [그림 Ⅲ-2-2]에서 TX1 트랜잭션을 참조하기 바란다.
Repeatable Read 트랜잭션 내에서 쿼리를 두 번 이상 수행할 때, 첫 번째 쿼리에 있던 레코드가 사라지거나 값이 바뀌는 현상을 방지해 준다. 이 트랜잭션 격리성 수준이 Phantom Read 현상을 막지는 못한다. 첫 번째 쿼리에서 없던 새로운 레코드가 나타날 수 있다는 것이다. 한 트랜잭션 내에서 쿼리를 두 번 수행했는데 두 쿼리 사이에 다른 트랜잭션이 새로운 레코드를 삽입하는 경우로서, [그림 Ⅲ-2-2]에서 TX1 트랜잭션을 참조하기 바란다.
Serializable Read 트랜잭션 내에서 쿼리를 두 번 이상 수행할 때, 첫 번째 쿼리에 있던 레코드가 사라지거나 값이 바뀌지 않음은 물론 새로운 레코드가 나타나지도 않는다.
트랜잭션 격리성 수준은 ISO에서 정한 분류 기준일 뿐이며, 모든 DBMS가 4가지 레벨을 다 지원하지는 않는다. 예를 들어, SQL Server와 DB2는 4가지 레벨을 다 지원하지만 Oracle은 Read Committed와 Serializable Read만 지원한다. (Oracle에서 Repeatable Read를 구현하려면 for update 구문을 이용하면 된다.) 대부분 DBMS가 Read Committed를 기본 트랜잭션 격리성 수준으로 채택하고 있으므로 Dirty Read가 발생할까 걱정하지 않아도 되지만, Non-Repeatable Read, Phantom Read 현상에 대해선 세심한 주의가 필요하다. 그런 현상이 발생하지 않도록 DBMS 제공 기능을 이용할 수 있지만, 많은 경우 개발자가 직접 구현해 주어야 하기 때문이다. 다중 트랜잭션 환경에서 DBMS가 제공하는 기능을 이용해 동시성을 제어하려면 트랜잭션 시작 전에 명시적으로 Set Transaction 명령어를 수행하기만 하면 된다. 아래는 트랜잭션 격리성 수준을 Serializable Read로 상향 조정하는 예시다.
set transaction isolation level read serializable;
트랜잭션 격리성 수준을 Repeatable Read나 Serializable Read로 올리면 ISO에서 정한 기준을 만족해야 하며, 대부분 DBMS가 이를 구현하기 위해 Locking 메커니즘에 의존한다. 좀 더??까지 유지하는 방식을 사용한다. 앞서 보았던 [그림 Ⅲ-2-1]를 예로 들어, TX1 트랜잭션을 Repeatable Read 모드에서 실행했다고 하자. 그러면 t1 시점에 ①번 쿼리에서 설정한 공유 Lock을 t6 시점까지 유지하므로 TX2의 ②번 update는 t6 시점까지 대기해야 한다. 문제는 동시성이다. [그림 Ⅲ-2-1]처럼 한 건씩 읽어 처리할 때는 잘 느끼지 못하는 수준이겠지만, 대량의 데이터를 읽어 처리할 때는 동시성이 심각하게 나빠진다. 완벽한 데이터 일관성 유지를 위해 심지어 테이블 레벨 Lock을 걸어야 할 때도 있다. 이에 대한 대안으로 다중버전 동시성 제어(Multiversion Concurrency Control)을 채택하는 DBMS가 조금씩 늘고 있다. ‘스냅샷 격리성 수준(Snapshot Isolation Level)’이라고도 불리는 이 방식을 한마디로 요약하면, 현재 진행 중인 트랜잭션에 의해 변경된 데이터를 읽고자 할 때는 변경 이전 상태로 되돌린 버전을 읽는 것이다. 변경이 아직 확정되지 않은 값을 읽으려는 것이 아니므로 공유 Lock을 설정하지 않아도 된다. 따라서 읽는 세션과 변경하는 세션이 서로 간섭현상을 일으키지 않는다. [그림 Ⅲ-2-2]를 예로 들면, TX2 트랜잭션에 의해 새로운 고객이 등록되더라도 TX1은 트랜잭션은 그 값을 무시한다. 트랜잭션 내내 자신이 시작된 t1 시점을 기준으로 읽기 때문에 데이터 일관성은 물론 높은 동시성을 유지할 수 있다.
데이터베이스 애플리케이션 병목 상태는 주로 잘못 디자인된 인덱스와 인덱스의 부족으로 인해 나타난다. 최적의 데이터베이스와 최상의 애플리케이션 성능을 위해서는 효율적인 인덱슬르 디자인하는 것이 가장 중요하다. 인덱스 유형에는 아래와 같이 여러가지가 존재한다.
클러스터형
비클러스터형 인덱스
고유한
Filtered
columnstore
Hash
메모리 최적화 비클러스터형
# 인덱스 디자인 기본 사항
일반적으로 책의 끝에는 책의 정보를 빠르게 찾을 수 있는 인덱스가 존재한다. 인덱스는 키워드의 정렬된 목록이며, 각 키워드 옆에는 각 키워드를 찾을 수 있는 페이지를 가리키는 페이지 번호 세트가 있습니다.SQL Server 인덱스도 다르지 않습니다.
SQL Server 인덱스는 테이블이나 뷰와 연결된 디스크상 또는 메모리 내 구조로, 테이블이나 뷰의 행 검색 속도를 높입니다. 인덱스에는 테이블이나 뷰에 있는 하나 이상의 열로 작성되는 키가 포함됩니다. 디스크상 인덱스에서 이러한 키는 SQL Server가 키 값과 연결된 행을 빠르고 효율적으로 찾을 수 있는 트리 구조(B-트리)에 저장됩니다.
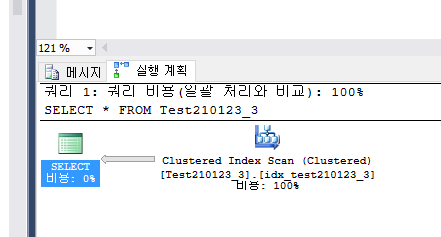
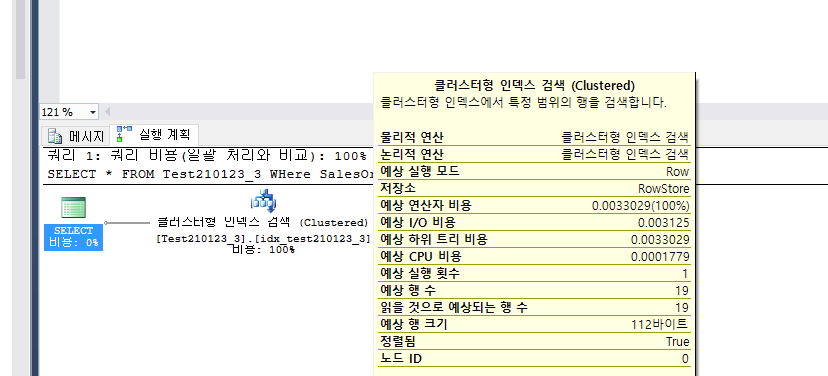
(특정 쿼리에 대해 쿼리 최적화 프로그램이 사용하는 인덱스를 확인하려면SQL Server Management Studio의쿼리메뉴에서실제 실행 계획 포함을 선택합니다.)
인덱스 사용이 항상 좋은 성능을 의미하지 않으며 마찬가지로 좋은 성능이 항상 효율적인 인덱스 사용을 나타내는 것은 아닙니다.인덱스 사용이 최상의 성능을 내는 데 항상 도움이 된다면 쿼리 최적화 프로그램의 작업은 간단할 것입니다.실제로 인덱스를 잘못 선택하면 최상의 성능을 얻지 못할 수 있습니다.따라서 쿼리 최적화 프로그램에서는 성능을 향상시킬 경우에만 인덱스나 인덱스 조합을 선택하고 성능을 저하시킬 경우에는 인덱싱된 검색을 피해야 합니다.
쿼리에 사용되는 열의 특성을 이해합니다.예를 들어 인덱스는 정수 데이터 형식을 사용하는 고유 열이나 Null이 아닌 열에 이상적입니다.테이블에 대한 인덱스를 많이 만들면 테이블의 데이터가 변경될 경우 인덱스도 모두 적절하게 조정되어야 하므로INSERT,UPDATE,DELETE및MERGE문의 성능이 저하될 수 있습니다.예를 들어 열이 여러 인덱스에서 사용되고 열 데이터를 수정하는UPDATE문을 실행하는 경우 열을 포함하는 각 인덱스뿐만 아니라 기본 테이블(힙 또는 클러스터형 인덱스)에 있는 열도 업데이트되어야 합니다.
인덱스는 특정 응용 프로그램을 위해서 생성되는 것이 아니다. 최소의 인덱스 구성으로 모든 접근 경로를 제공할 수 있어야 전략적인 인덱스 설계가 된다. 따라서 인덱스 선정은 테이블에 접근하는 모 든 경로를 수집하고 수집된 결과를 분석하여 종합적인 판단에 의해서 결정되는 것이 바람직하다.인덱스는 특정 애플리케이션을 위해서 생성되는 것이 아니다. 최소의 인덱스 구성으로 모든 접근 경로를 제공할 수 있어야 전략적인 인덱스 설계가 된다. 따라서 인덱스 선정은 테이블에 접근하는 모 든 경로를 수집하고 수집된 결과를 분석하여 종합적인 판단에 의해 결정하는 것이 바람직하다.
- 접근 경로 수집
접근 경로는 테이블에서 데이터를 검색하는 방법으로, 테이블 스캔과 인덱스 스캔 등이 있다. 접근 경로를 수집한다는 의미는 SQL이 최적화되었을 때 인덱스 스캔을 해야 하는 검색 조건들을 수집하 는 것이므로 데이터베이스 설계 시 혹은 완성되지 않은 프로그램에서 사용될 모든 접근 경로를 예측 하기는 불가능하다. 따라서 프로그램 설계서, 화면 설계 자료, 프로그램 처리 조건 등을 고려하여 예 상되는 접근 경로를 수집하여야 한다. 수집은 테이블 단위로 진행하고, 다음과 같은 점을 고려하여 접근 유형을 목록화한다.
- 반복 수행되는 접근 경로
대표적인 것이 조인 칼럼이다. 조인 칼럼은 FK 제약 대상이기도 하다. 주문 1건당 평균 50개의 주 문 내역을 갖는다면 주문 테이블과 주문 내역 테이블을 이용하여 주문서를 작성하는 SQL은 조인 을 위해 평균 50번의 주문 내역 테이블을 반복 액세스한다.
- 분포도가 양호한 칼럼
주문번호, 청구번호, 주민번호 등은 단일 칼럼 인덱스로도 충분한 수행 속도를 보장 받을 수 있는 후보를 수집한다.
- 조회 조건에 사용되는 칼럼
성명, 상품명, 고객명 등 명칭이나 주문일자, 판매일, 입고일 등 일자와 같은 칼럼은 조회 조건으 로 많이 이용되는 칼럼이다.
- 자주 결합되어 사용되는 칼럼
판매일 + 판매부서, 급여일+급여부서와 같이 조합에 의해서 사용되는 칼럼 유형을 조사한다.
- 데이터 정렬 순서와 그룹핑 칼럼
조건뿐만 아니라 순방향, 역방향 등의 정렬 순서를 병행하여 찾는다. 인덱스는 구성 칼럼 값들이 정렬되어 있어 인덱스를 이용하면 별도의 ORDER BY에 의한 정렬작업이 필요 없다. 동일한 원리 로 그룹핑 단위(GROUP BY)로 사용된 칼럼도 조사한다.
- 일련번호를 부여한 칼럼
이력을 관리하기 위해서 일련번호를 부여한 칼럼에 대해서도 조사를 실시한다. 마지막 일련번호를 찾는 경우가 빈번히 발생하므로 효과적인 액세스를 위해서 필요하다.
- 통계 자료 추출 조건
통계 자료는 결과를 추출하기 위해서 넓은 범위의 데이터가 필요하다. 따라서 다양한 추출 조건을 사전에 확보하여 인덱스 생성에 반영하여야 한다.
- 조회 조건이나 조인 조건 연산자
위에 제시되는 유형의 칼럼과 함께 적용된 =, between, like 등의 비교 연산자를 병행 조사한다. 이는 인덱스 결합 순서를 결정할 때 중요한 정보로 사용된다.
위에서 제시되는 칼럼들은 인덱스 생성이 필요한 칼럼들이다. 운영 중인 시스템을 대상으로 인덱 스를 설계할 때는 사용하고 있는 애플리케이션 내에 SQL 문장을 수집하거나 트레이스(Trace)를 사 용해 SQL들을 추출하여 접근 경로를 수집할 수 있다. 사후 작업은 많은 공수가 필요하지만 정확한 접근 경로를 추출할 수 있다. 따라서 설계 단계에서 위와 같은 칼럼으로 접근 경로로 추출해 인덱스 설계에 이용하고, 개발이 완료된 후 시스템 운영 초기나 성능에 문제가 발생되었을 때 인덱스 설계를 보완하는 것이 일반적인 형태이다.