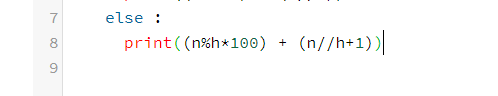푸는데 꼬박 2일걸렸다.. 물론 일이 바빠서 제대로 푼건 몇시간 안되지만
역시 시작을 잘못 시작하게 되면 계속 꼬이게 되는 걸 경험했다.
처음엔 3으로 빼면서 5로 나눈 카운트를 구하고 5로 빼면서 3으로 나눈 카운트를 각각 구했는데
잘 안풀렸다.
결국엔 처음부터 다시 입력 조건 별로 확인해보니 무조건 3씩 빼면서 5로 나눴을때 나머지가 없으면 최소가 된다는 것을 확인하고 금방 풀렸다.
문제 풀기 전! 밑그림이 가장 중요하다.
8번만에 성공 ㅋㅋㅋ
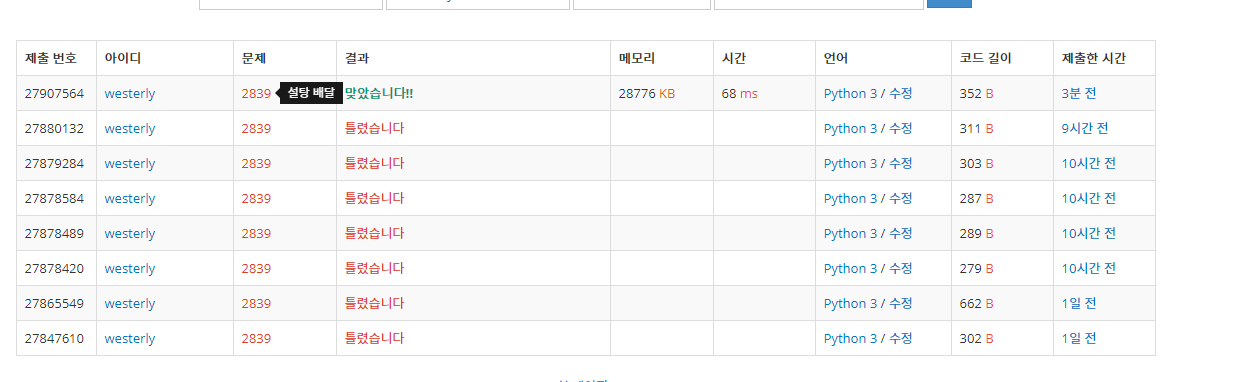
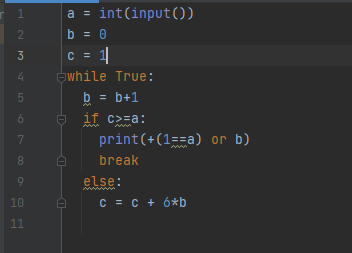
내 풀이 :

'Baekjoon' 카테고리의 다른 글
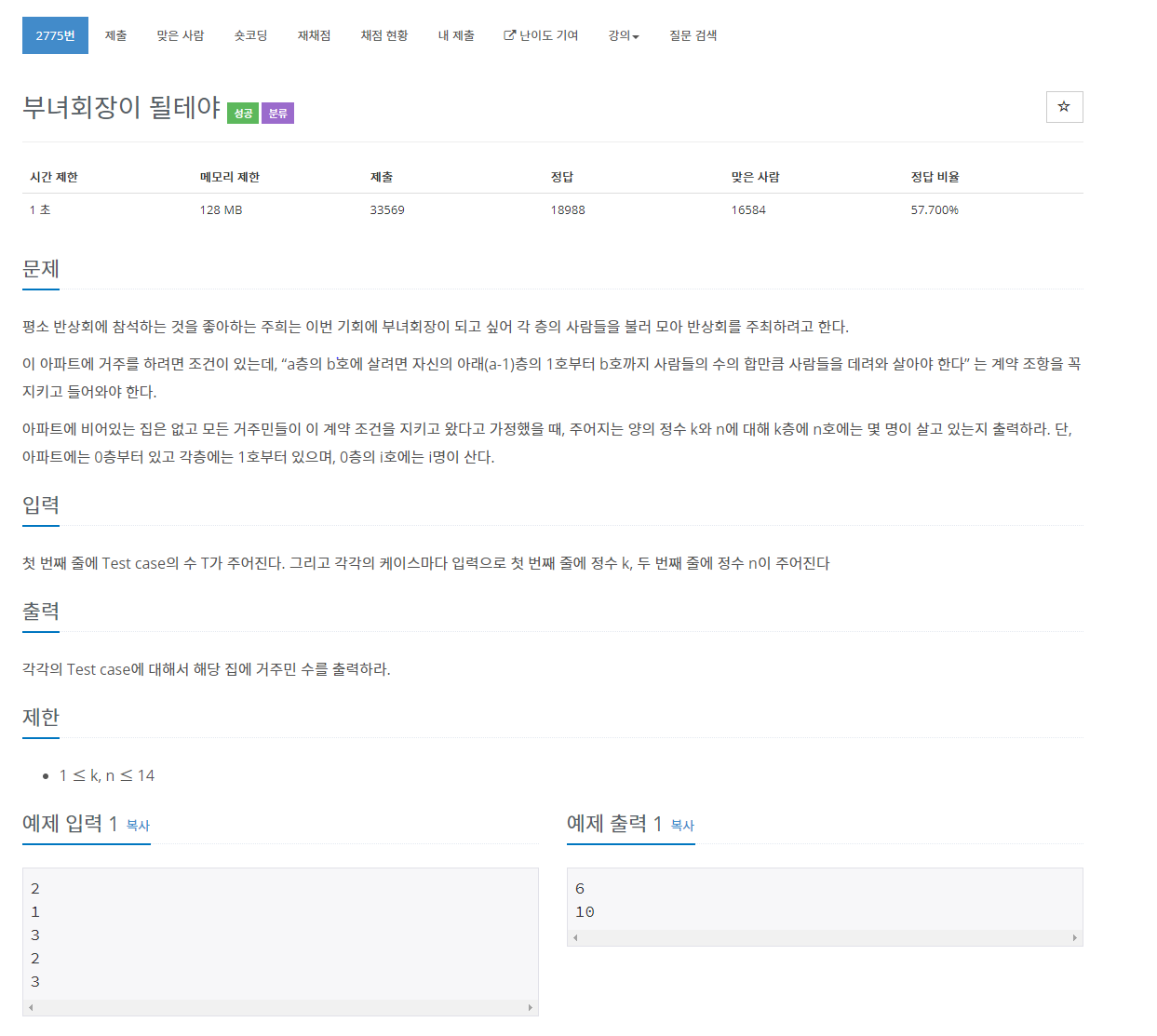
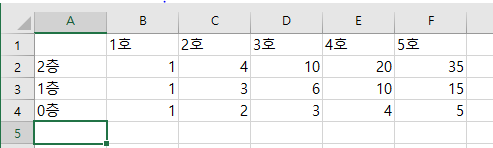
| [Baekjoon][Python] 2775 부녀회장이 될테야 (0) | 2021.03.30 |
|---|---|
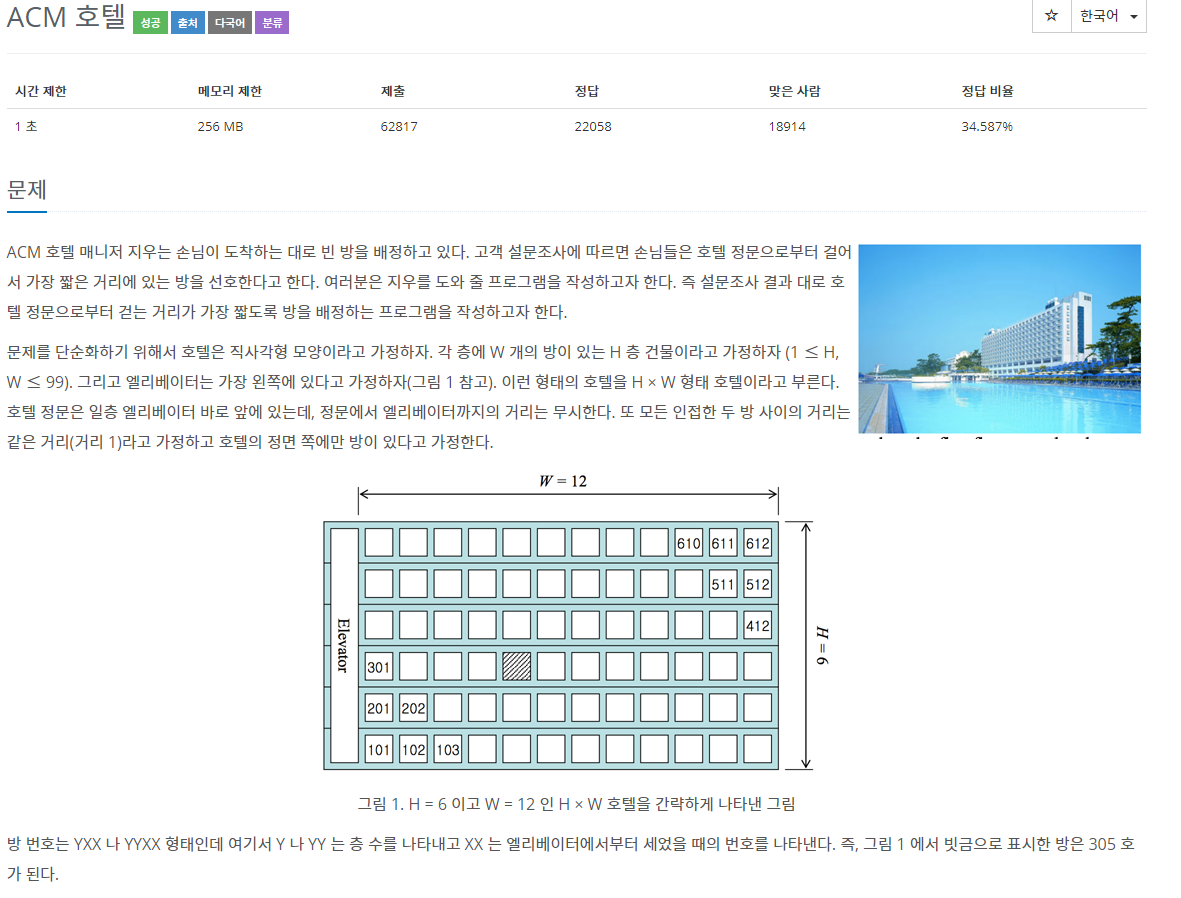
| [Baekjoon][Python] 10250 ACM호텔 (0) | 2021.03.22 |
| [Baekjoon][Python] 2869 달팽이는 올라가고 싶다 (0) | 2021.03.19 |
| [Baekjoon][Python] 1193 분수찾기 (0) | 2021.03.18 |
| [Baekjoon][Python] 2292 벌집 (0) | 2021.03.17 |